|
(第
1
篇)
 我中國
於 2025/1/30 下午 06:03:00
說:
我中國
於 2025/1/30 下午 06:03:00
說: |
針對第七題
DeepSeek得分較低似乎是因為未能理解題幹中“證明”的含義,僅僅重述了待證明的結論,無法得分
GPT-o1總分與DeepSeek相差無幾
相比于DeepSeek,o1的答卷更接近于人类的风格,因此以证明题为主最后一题(第七題)得分稍高。
然後!
我們看一下,第七題是什麼?
(這真的是共匪的科學教育嗎?)

|
|
|
(第
2
篇)
我中國
於 2025/1/30 下午 06:13:00
說: |
這是人工智能回答的分數!
若以理工專業來說,
DS略勝GPT
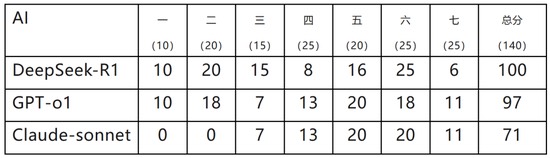
列舉
第一題是什麼東西?
(共匪…正忙著星辰大海)

|
|
|
(第
3
篇)
我中國
於 2025/1/30 下午 06:16:00
說: |
糟糕了…
這場競賽的對象是「高中生」
(別開玩笑了,你台灣要跟共匪對抗?)
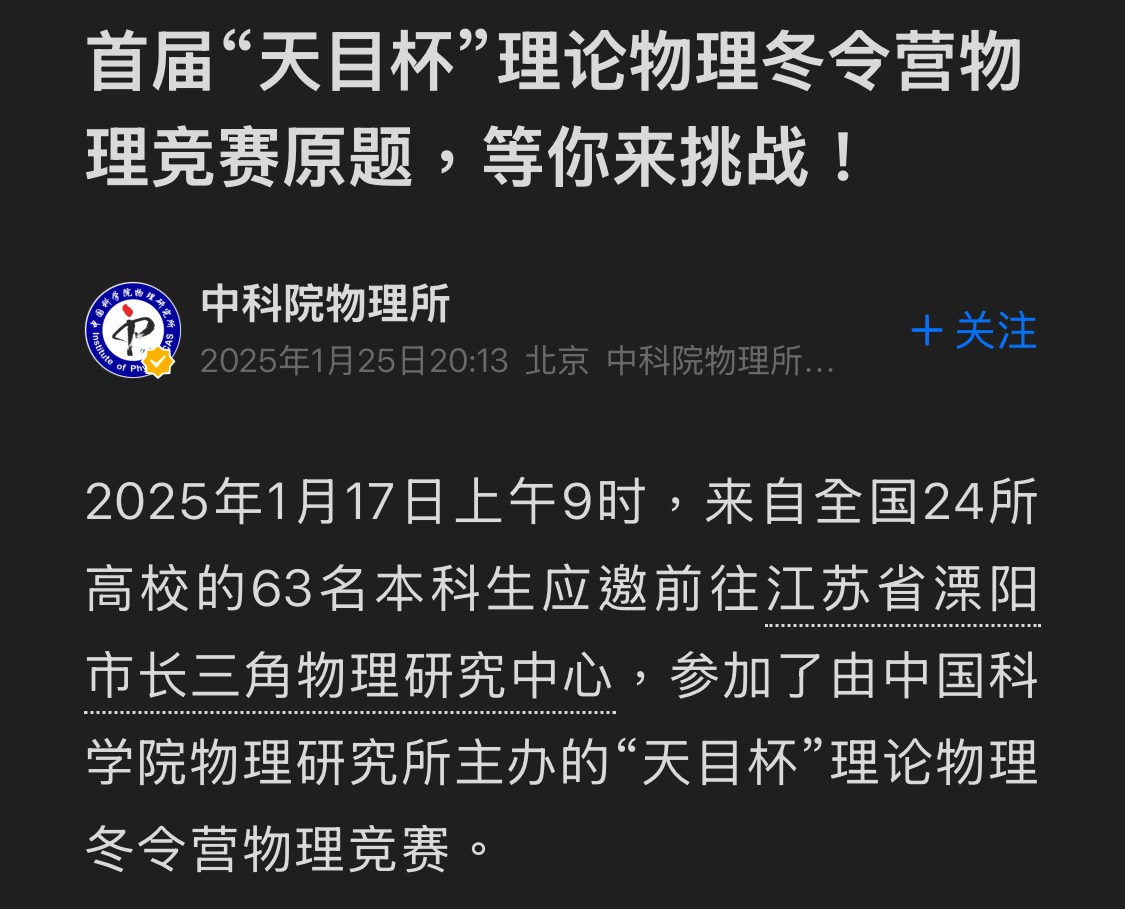
|
|
|
(第
4
篇)
我中國
於 2025/1/30 下午 06:26:00
說: |
我中國…
出這種題目考高中生
可想見。
卯足全力…
14億茫茫人口,
尋找愛因斯坦
|
|
|
(第
5
篇)
我中國
於 2025/1/30 下午 06:43:00
說: |
然後!
一代又一代,一年又一年!
只要「每十年」…
能找到一個「中國版」的愛因斯坦!
共產黨
就無愧於先聖先賢、列祖列宗!
|
|
|
(第
6
篇)
我中國
於 2025/1/30 下午 06:46:00
說: |
習近平的野心…很大
遠超過秦皇漢武
|
|
|
(第
7
篇)
好文要看!
於 2025/1/30 下午 07:15:00
說: |
好文要看!
|
|
|
(第
8
篇)
好文要看!
於 2025/1/30 下午 07:29:00
說: |
好文要看!
|
|
|
(第
9
篇)
好文要看!
於 2025/1/30 下午 07:44:00
說: |
好文要看!
|
|
|
(第
10
篇)
.
於 2025/1/30 下午 08:01:00
說: |
.
|
|
|
(第
11
篇)
我中國
於 2025/1/30 下午 08:05:00
說: |
當年!
蔣介石與毛澤東!
同期策反「錢學森」
(結果…不重要)
重點是:
「錢學森彈道火箭定律」…至今仍被美國奉為圭臬!
備註:
錢學森年幼無知,
在美國講了一些他不知道
很可能會亡國滅種的科學定律
|
|
|
(第
12
篇)
看!
於 2025/1/30 下午 08:14:00
說: |
看!
|
|
|
(第
13
篇)
戳起來!
於 2025/1/30 下午 09:05:00
說: |
戳起來!
|
|
|
(第
14
篇)
.
於 2025/1/30 下午 09:30:00
說: |
.
|
|
|
(第
15
篇)
這篇要看!
於 2025/1/30 下午 11:31:00
說: |
這篇要看!
|
|